Overview
The Link checker module scans all links in your site (both internal and external) to detect any links that are broken or inactive. This tool helps you find and fix broken links far more efficiently than manually checking the contents of every node.
Links can break for a number of reasons, such as:
- An article may be archived or deleted.
- A provider may leave the organization.
- A department may be sunset.
In these cases, any links to that content in any other published content will result in a 404 "not found" error (and a bad experience) for your end users.
The Link checker, when set up, routinely scans for broken links and generates a report you can use to easily address each link issue.
For step-by-step instructions on using Link scanner's Broken links report to fix links, please see our How-to article.
Jump to:
Setting which content is scanned
Please contact support for setting up Link checker and selecting content to scan for broken links.
Configuring Link checker
After Link checker is enabled, you can access it by clicking Configuration in the Toolbar; then under Content authoring, click Link checker.
General settings
These are the overall settings for the Link checker process.
- What types of links should be checked?: The links that Link checker will scan to see whether the link is broken. Options are Internal, External, or Internal and external.
- An internal link is a link that doesn't explicitly state a domain and uses the current domain by default (e.g., an absolute link like "/news/research-update" or a relative link like "/node/123")
- An external link is a link that explicitly states a domain name in the link target (e.g., "https://example.com/news/research-update")
- Default URL scheme: The default URL scheme that Link checker should use to check relative (internal) links. Options are HTTP or HTTPS. In almost all cases, this should be set to HTTPS.
- Base path: The default base path to insert for internal links (e.g., "www.example.com"). Leave this blank to use the base path for your site.
- Search published contents only: Check this box to skip scanning for broken links on pages that are not accessible to the public.
Link extraction
These settings allow for scanning links inside of special HTML tags.
- Extract links in <a> and <area> tags: Enable this checkbox if normal hyperlinks should be extracted. The anchor element defines a hyperlink, the named target destination for a hyperlink, or both. The area element defines a hot-spot region on an image, and associates it with a hypertext link.
- Extract links in <audio> tags including their <source> and <track> tags: Enable this checkbox if links in audio tags should be extracted. The audio element is used to embed audio content.
- Extract links in <embed> tags: Enable this checkbox if links in embed tags should be extracted. This is an obsolete and non-standard element that was used for embedding plugins in past and should no longer used in modern websites.
- Extract links in <iframe> tags: Enable this checkbox if links in iframe tags should be extracted. The iframe element is used to embed another HTML page into a page.
- Extract links in <img> tags: Enable this checkbox if links in image tags should be extracted. The img element is used to add images to the content.
- Extract links in <object> and <param> tags: Enable this checkbox if multimedia and other links in object and their param tags should be extracted. The object tag is used for flash, java, quicktime and other applets.
- Extract links in <video> tags including their <source> and <track> tags: Enable this checkbox if links in video tags should be extracted. The video element is used to embed video content.
Text formats disabled for link extraction
Select any of the following options to process certain code elements differently before scanning for links. These adjustments can expose (or hide) more links to Link checker's scanning procedure.
- Embedded content: Converts <embedded-content> tags to results.
- Track images uploaded via a Text Editor: Ensures that the latest versions of images uploaded via a Text Editor are displayed, along with their dimensions.
- Align images: Uses a data-align attribute on <img> tags to align images.
- Correct faulty and chopped off HTML: Automatically tries to correct erroneous or incomplete HTML before scanning.
- Caption images: Uses a data-caption attribute on <img> tags to caption images.
- Lazy load images: Instruct browsers to lazy load images if dimensions are specified. Use in conjunction with and place after the 'Track images uploaded via a Text Editor' filter that adds image dimensions required for lazy loading. Results can be overridden by <img loading="eager">.
- Display any HTML as plain text
- Convert URLs into links
- Convert line breaks into HTML (i.e. <br> and <p>)
- Restrict images to this site: Disallows usage of <img> tag sources that are not hosted on this site by replacing them with a placeholder image.
- Limit allowed HTML tags and correct faulty HTML: Reduces the amount of non-basic URL tags that are rendered and attempts to correct any discrepancies caused by that restriction.
- Enable alert tokens: Replace [alert|URL] with alert text from another Mercury Web Framework website.
- Enable site details tokens: Replace [site_name], [slogan], and [email_address] with their values under Basic Site Settings.
- Correct relative links: Replace relative links with their canonical destinations.
- Linkit URL converter: Updates links inserted by Linkit to point to entity URL aliases.
- Embed media: Embeds media items using a custom tag, <drupal-media>. If used in conjunction with the 'Align/Caption' filters, make sure this filter is configured to run after them.
- Replaces global and entity tokens with their values: Replace any global or entity tokens with the value that would appear on a rendered page. For instance, replace [currnent-page:metatag:keywords] with the text keywords assigned to the node.
Check settings
These options apply to the link scanning function itself. In most cases, the default values are sufficient.
- Check library: Defines the library that is used for checking links.
- Number of simultaneous connections: Defines the maximum number of simultaneous connections that can be opened by the server. Make sure that a single domain is not overloaded beyond RFC limits. For small hosting plans with very limited CPU and RAM it may be required to reduce the default limit.
- User-Agent: Defines the user agent that will be used for checking links on remote sites. If someone blocks the standard Drupal user agent you can try with a more common browser.
- Check interval for links: Defines how often the Link checker will re-check the status of links.
- Do not check the link status of links containing these URLs: Defines any URLs that Link checker should ignore, like URLs that are only written to exemplify or demonstrate something for your visitor (e.g., "example.com," "example.net," or "example.org"). URLs on this list are still extracted, but the link setting Check link status becomes automatically disabled to prevent false alarms.
- Log level: Controls the severity of events that are captured in logs.
Error handling
These settings tell Link checker what to do with any link errors it finds.
- Impersonate user account: Tells Link checker to impersonate a user when making any automatic changes. You can change the default user here to a custom one to track the changes it makes more easily. Learn more about managing users.
- Update permanently moved links: Indicates when Link checker should change the URL for a link that consistently redirects to another link (status code 301). Options are Disabled (never), or after 1, 2, 3, 5, or 10 failed checks.
- Unpublish content on file not found error: Defines when Link checker should automatically unpublish content that has broken links. Options are Disabled (never), or after 1, 2, 3, 5, or 10 failed checks.
- Don't treat these response codes as errors: Lists the server response codes that Link checker should not flag as a broken link. Add one server response code per line here. Common codes to consider are:
- 200: OK / successful response.
- 206: Partial content - only some of the content was returned successfully (e.g., an incomplete file download).
- 302: Found - the link temporarily redirects to another destination.
- 304: Not modified - the data at the destination link hasn't changed since the browser last cached the site contents.
- 401: Unauthorized - the link requires authentication that is not provided.
- 403: Forbidden - the destination server requested and received authentication, but the data or action requested is not permitted.
Maintenance
These buttons allow you to run the Link checker on demand. The Link checker will run automatically on a regular schedule, so there's normally no need to use these buttons.
- Reanalyze content for links: Runs the Link checker using the existing settings. The tables that Link checker uses to track changes remain intact.
- Clear link data and analyze content for links: Runs the Link checker using the existing settings. The tables that Link checker uses to track changes are deleted and re-built.
Broken links report
Access the Broken links report by clicking Reports in the Toolbar, then Broken links. The table will display a list of all broken links discovered by Link checker.
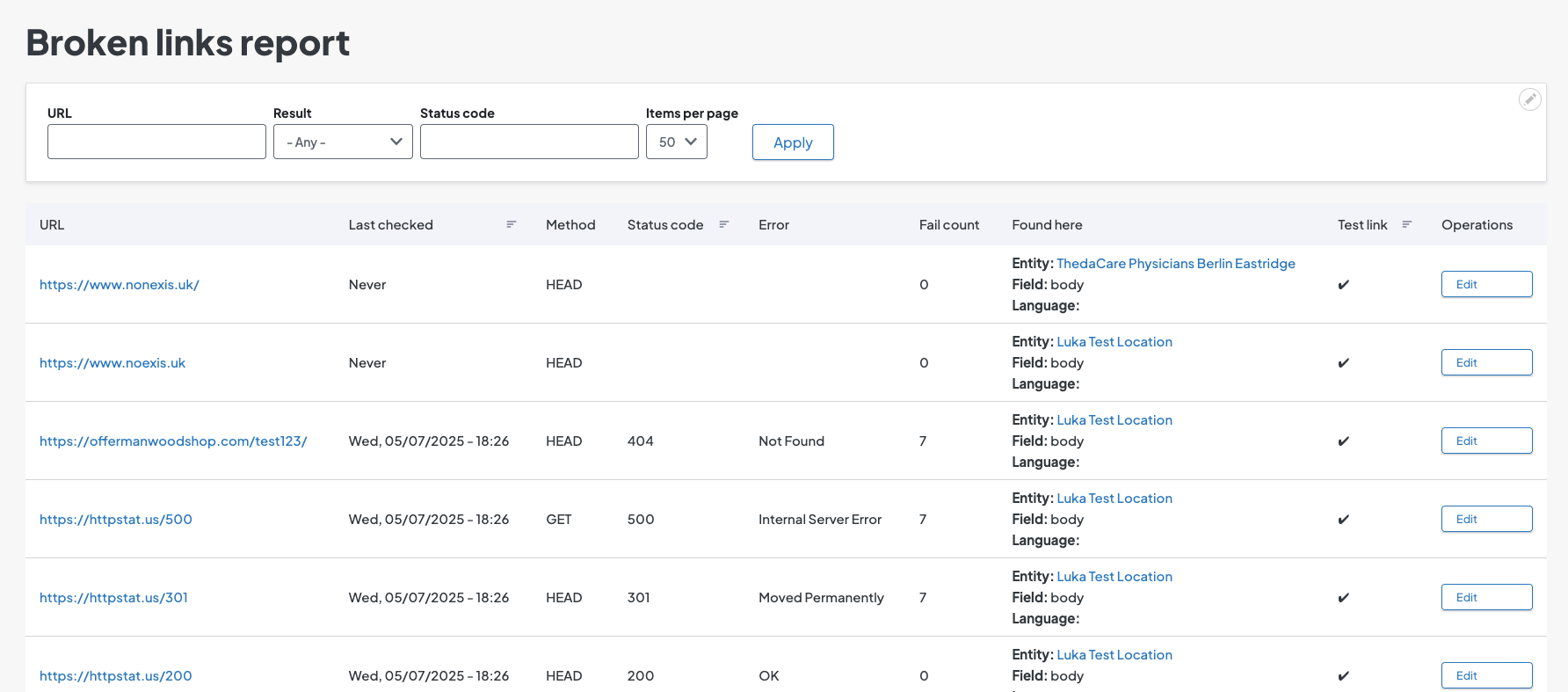
Report field definitions
- URL: The target of the link that was found to be broken.
- Last checked: The last time Link checker scanned this link.
- Method: How Link checker scanned the destination:
- HEAD: Link scanner only checked the header of the destination to get metadata, such as last time it was updated.
- GET: Link scanner requested the header metadata and the body content of the destination.
- Status code: The server status code returned from the server.
- Error: The text description of the status code.
- Fail count: The number of consecutive times this link has failed when Link checker scans it.
- Found here: The node title, field, and language (if applicable) where the broken link is.
- Test link: A checkmark here indicates the link has been identified as a test link.
- Operations: An Edit button for changing how this link is treated by Link scanner.
Edit button options
- Request method: Changes how Link scanner tests this link. Options are:
- HEAD: Only look at the header metadata. This verifies whether the link is valid and gets helpful metadata while saving some processing time by skipping over the destination content.
- GET: Request the full body of the destination link. This allows Link checker to gather more complete info, such as whether the link results in a partial success or authentication error.
- Check link status: Uncheck this to tell Link checker to ignore scanning this link in the future.
Related Help Content
 DXE: Builder basics
DXE: Builder basics
Assigning color values
Colors are added to your DX Engine site in a few steps. For those brand new to web design, that may sound...
DXE: Builder basics
Missing Content Reference Report
OverviewThe Missing Content Reference Report checks your site for any DXE content that has been deleted o...
DXE: Builder basics
Building a brand
Building your brand in DXE is a critical part of establishing your online presence. DXE includes hundreds...
DXE
Accessibility support
WebMD Ignite is committed to providing health content and solutions that are relevant, relatable, and hel...
DXE: Adding content
How-to: FAQ Group
OverviewThe FAQ Group component is a specialized accordion designed for FAQ content. Key differences from...
DXE: Adding content
Blocks (shared elements)
SummaryA “block” is a section of user created/configured content. You would generally use a block whe...